スキャンされた資料など透明テキストが付いていないPDFの場合、音声読み上げ等を行うためにはテキストデータを作成する必要があります。今回は印刷された文字を認識するOCRソフトを活用したテキストデータの作成についてご紹介します。
以下の記事とあわせてTips(テキストデータ化 ver.1.2)をご参照ください。
Index
Index
スキャン作業
書籍やレジュメ等の印刷された資料は、スキャナーでスキャンすることでPDFなどの電子データに変換します。スキャン方法を工夫することでOCRを行った際の文字認識の精度が大きく向上します。以下の点に注意してスキャンしていきます。
解像度
スキャンする際の解像度を最大に設定します。初期設定では「200dpi」で設定されていることが多いため、可能であれば、「600dpi」のように高解像度に設定します。高解像度でスキャンすることにより、スキャンした際の文字のかすれや潰れを防ぐことができ、結果的に文字認識の精度を向上させる事ができます。
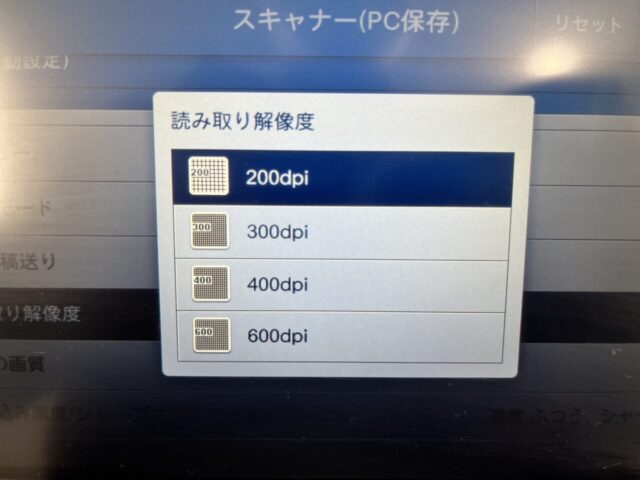
スキャナーの解像度設定
資料の傾き
スキャンする際に資料が傾いているとOCRの認識精度が下がることがあります。そのため、資料が傾かないように注意してスキャンする必要があります。また、厚さのある書籍等をスキャンする際は特に注意が必要です。上から押さえつける力が均等でないとスキャンの際に書籍が浮き上がり、傾きやすくなります。

文章の部分が傾いたPDF
裁断
書籍に厚みがある場合や、背表紙が固く開きづらい場合に見開きでスキャンすると、中央部分に影ができ、文字を黒く塗りつぶすことがあります。影のある状態でOCRすると、影の部分が正しく認識されないため、誤認識が多くなります。できるだけ影が文字と重ならないように書籍を押さえつけてスキャンします。押さえつけても影と文字が重なる場合は、書籍の裁断を検討します。裁断することで複合機の自動原稿送り装置を使用することができるため、影の無いきれいなPDFデータを作成することができます。加えて自動でページが送られていくのでスキャンにかかる時間を大幅に減らすことができます。なお書籍を裁断する際は、裁断可能か確認が必要です。裁断が難しい場合はScanSnap SV600などを検討しても良いでしょう。

大きな書籍を裁断できる裁断器

複合機の自動原稿送り装置
OCR
スキャンで作成したPDFはOCRソフトを使用して文字認識をしていきます。OCRソフトによっては多言語に対応しているものや、PDFの傾きを補正するものもあります。
PDFページ内の認識させたいところを選択し、文字認識をしていきます。選択範囲から章のタイトルやページ番号を除くことで不要な文字列が認識されるのを防ぎます。また、段組み等がされている場合は文字認識していく順序を決めることで文章の順番通り文字認識させることができます。
詳しいOCRソフトの使い方は使用するソフトによって異なるため、説明書等で確認してください。
<OCRアプリの一例>
・WinReader PRO(Windows)
多言語に対応しているほか、日本語の文章中にある英語も認識できる。体裁上の改行を認識して省く機能や傾きの補正など細かな設定が可能であるが、設定項目が多いため操作方法に慣れる必要がある。
・読取革命(Windows)
シンプルな操作で使用することができる。傾き補正などの設定も可能。
・一太郎Pad(iOS, iPad)
内蔵カメラで撮影した画像を電子文書化することができる。写真を撮影すると自動的にOCR機能が動く。アカウントが不要な点が特徴。
・Googleドキュメント
Google Driveにアップロードした画像データ(PDF等)をGoogleドキュメントで開くことで文字認識をすることができる。
校正
OCRソフトで文字認識をすると必ず誤認識が生じます。そのため誤認識を修正する「校正」とよばれる作業が必要になります。Word等のテキストエディターにOCRで得られたテキストを貼り付けて校正を進めていきます。校正する際は国立国会図書館の「学術文献の視覚障害者等用テキストデータ製作仕様書」を参考にすると良いでしょう。仕様書はあくまで一例であるため、テキストデータを利用する学生のニーズによって仕様を変更する必要があります。
誤認識の修正
ひらがなでは「あ」と「お」、アルファベットでは「O」と「Q」などのように似ている文字では誤認識が生じやすくなります。また、書籍等が古く文字がかすれている場合や、文章の中に英語と日本語が混じっている場合などに誤認識が多くなる傾向があります。書籍の状態を確認し修正作業の負荷を見積もることも重要です。
誤認識の修正は、原本である書籍やPDFとOCRから得られたテキストデータを見比べながら行っていきます。大きめのディスプレイにPDFとテキストデータを並べて見比べながら修正していくなど作業しやすい方法で取り組むと良いでしょう。
不要改行の削除
点字ディスプレイ等で閲覧する際に読みやすいよう体裁を整える必要があります。OCRした直後のテキストデータには体裁上の改行が入っているため、不要な改行を削除していく必要があります。Wordの置換機能を使用すれば一括で改行を削除できます。ただし、段落等の必要な改行も削除されるため注意が必要です。
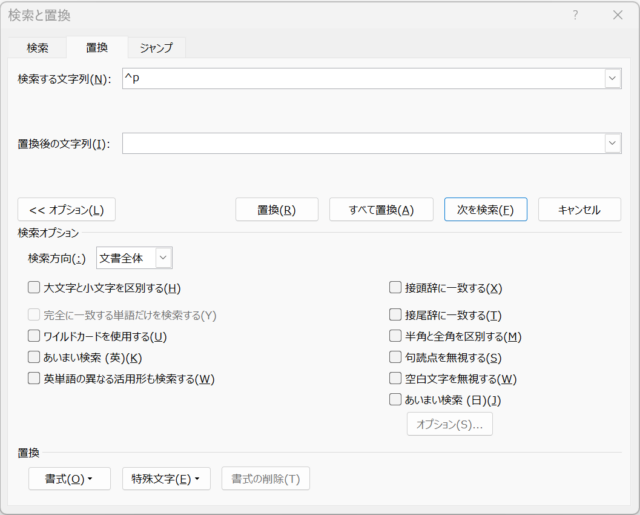
「あいまいな検索」のチェックを外すし、「特殊文字」から「段落記号(P)」を選択すると段落を表す「^p」が検索する文字列に挿入される。
ページ番号の挿入
提供するテキストデータには書籍のページと対応したページ番号を挿入しておきます。ページ番号があることによって巻頭の目次を活用できます。
図表の代替テキスト
図表がある場合は、どのような物が書かれているか文章で説明する代替テキストを作成する必要があります。どのような図表なのか客観的に説明すると良いでしょう。図をどこまで文章で説明するかは迷うところですが、テキストデータを利用する学生と相談して説明の詳しさを決めていきます。
txtへの書き出し
最終的にtxtファイルに書き出します。Wordを使用して校正を行っていた場合は、「名前をつけて保存」から「書式なし(*.txt)」の形式で保存します。最後に作成したtxtファイルがメモ帳で開けることを念のため確認しておくと良いでしょう。
<文字コードについて>
txt形式でデータを保存する際に「文字コード」を選ぶことができます。文字コードとはコンピューターで文字を処理する際に文字の種類に番号をふったものです。代表的なものには「Shift-JIS」や「UTF-8」がありますが、「Shift-JIS」は文字化けすることがあるので、できるだけ「UTF-8」で保存すると良いでしょう。
補足:国立国会図書館へのデータ提供
作成したテキストデータは国立国会図書館に提供することで多くの方がアクセスできるようになります。ただし、提供できるテキストデータには条件があるので、国立国会図書館のウェブサイトを(https://www.ndl.go.jp/jp/library/supportvisual/supportvisual-10_01.html)参考にしてください。
参考
公開日:2023年3月28日
以下のGoogleフォームからあなたの感想や要望をお聞かせください。
https://forms.gle/4DkKF5ns13sxzRRk8