音声認識アプリでは単語登録をすることで認識の精度が向上します。単語登録には1単語ずつ登録していく方法の他に単語と読みを一覧にしたCSVファイルをインポートして一括登録する方法があります。一括で単語登録をする場合、登録する単語の一覧をあらかじめCSVファイルで作成しておく必要があります。しかし、登録する単語数が多いほどCSVの作成に負担が生じます。そこで、HEAPではテキストデータから単語(名詞)を抽出しCSV形式で自動で書き出すプログラムを作成しました。
今回のAT ColumnではHEAPが作成した単語抽出プログラム「HEAP Word Extractor(以下、HWE)」を活用して単語登録の負担を軽減する方法をご紹介します。
※本プログラムの作成にあたっては、プログラミングにお詳しい浅田氏にご協力いただきました。ご協力に感謝いたします。
Index
Index
「HWE」とは
「HWE」はHEAPが作成した名詞抽出プログラムでGoogleが提供しているブラウザ上でPythonを記述・実行できるGoogle Colaboratoryというサービスを使用しています。従来、Pythonで記述されたプログラムを実行するには、PCにPythonをインストールして環境を構築する必要がありました。このPythonの環境構築にはコマンドプロンプトを使用するなど、一定の専門的な知識が必要であり、支援部署で使用するには大きなハードルがありました。そこでHEAPでは、複雑な環境構築が不要なGoogle Colaboratoryでプログラムを実行できるようにし、数回のクリックでテキストデータから名詞の抽出が行えるようにしました。Google Colaboratoryの実行ボタンを順番にクリックしていくことで、単語登録に必要な単語と単語の読みが一覧になったCSVファイルを作成することができます。
注意事項
使用者がHWEプログラムを実行する際はHEAPで作成したプログラムの「コピー」を使用者のGoogle Drive上で実行しています。HEAPが使用者のGoogle Drive内を閲覧できるわけではありませんので安心してお使いください。プログラム実行中にパスを編集する際など誤って操作してしまった場合であっても、HEAPのオリジナルには影響はありません。また、ご自身のGoogle Driveにコピーを保存することで、編集することも可能ですので、使いやすいように改変していただいて構いません。([ファイル>ドライブにコピーを保存]で使用者のGoogle Driveに保存ができます。)
なお、このプログラムではテキストデータ中に2回以上出てきた単語を抽出の対象としているため、出現頻度が1回のみの単語はCSVの一覧に含まれません。
テキストデータの準備
HWEで単語を抽出するには元となるテキストデータが必要になります。講義資料等のWordやPDFからテキストデータ(拡張子「.txt」)を作成します。
Wordの場合は、[ファイル>名前を付けて保存]から[書式なし(*.txt)]を指定して保存します。その際に文字コードは「Unicode(UTF-8)」を指定しておく必要があります。
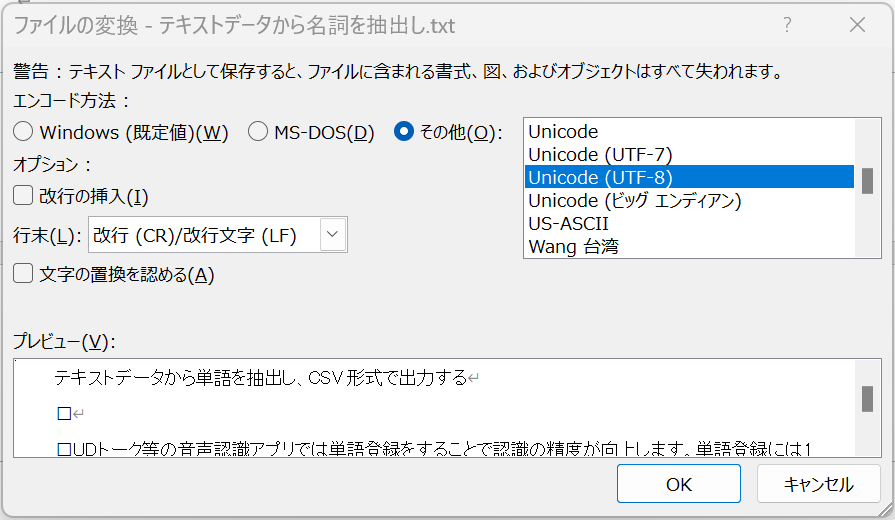
また、PDFの場合はAdobe Acrobatを使用し、[ファイル>書き出し形式>テキスト(プレーン)]を指定します。作成したtxtファイルは文字コードが「ANSI」になっているため、txtファイルをメモ帳で開き、[ファイル>名前を付けて保存]からエンコードを「UTF-8」にして保存し直す必要があります。

なお、PowerPointファイルの場合は、一度PDF形式で保存してから上記の方法でテキストデータに変換します。
作成したテキストデータはGoogle Driveに任意のフォルダを作成しその中にアップロードしておきます。
Google Colaboratory上でのプログラム実行(3ステップ)
以下のURLよりHWEのページにアクセスします。
https://colab.research.google.com/drive/158X0VegJNDTdB9hnjrtYylJeKvLIwJG3?usp=drive_link
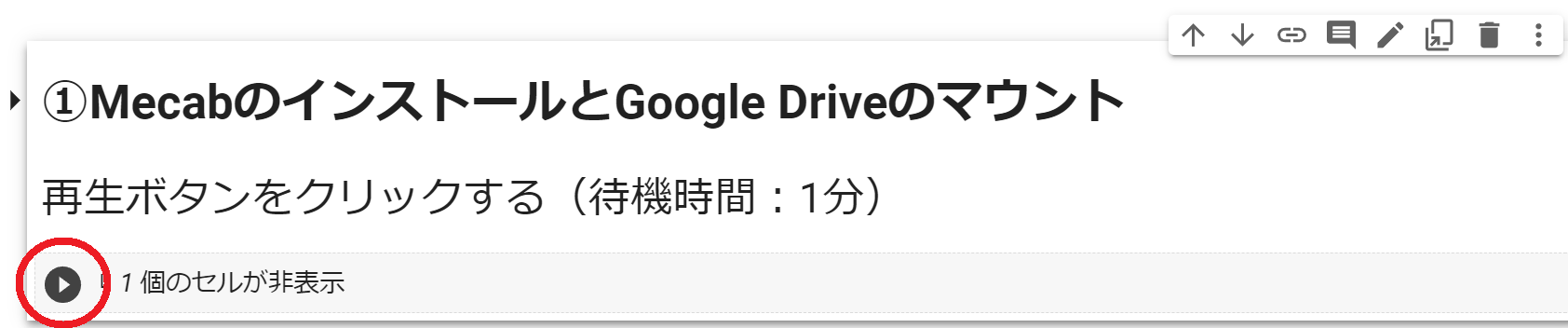
1.MecabのインストールとGoogle Driveのマウント
単語を抽出するために「Mecab」という形態素解析エンジンを使用します。再生ボタンをクリックすることでMecabがGoogle Colaboratoryにインストールされます。
インストールが進むと次のような画面が出てきますが、「このまま実行」をクリックします。

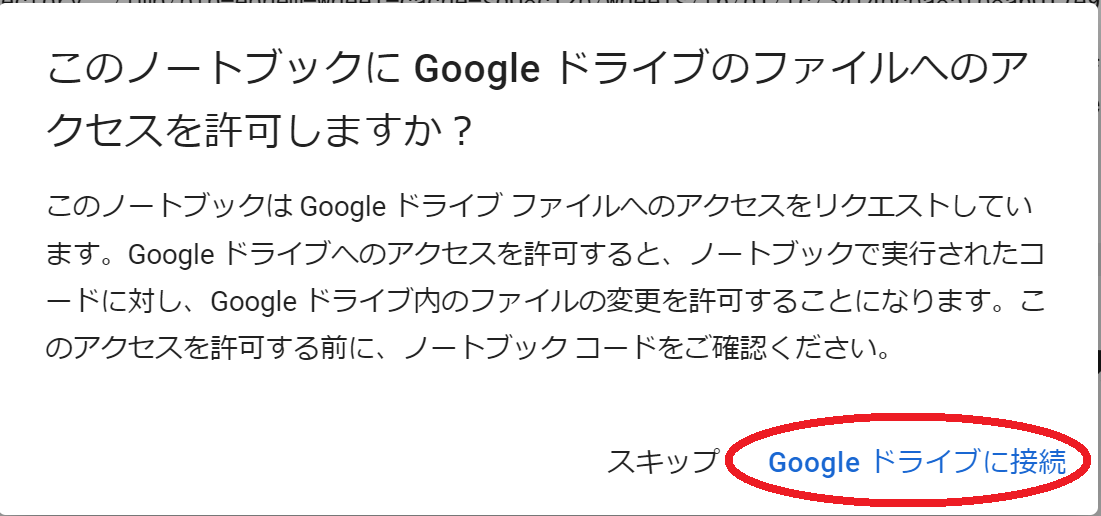
さらにインストールが進むと次のような画面が出てくるので「Googleドライブに接続」をクリックします。Googleドライブに保存したテキストデータを使用するためにGoogleドライブを使用します。
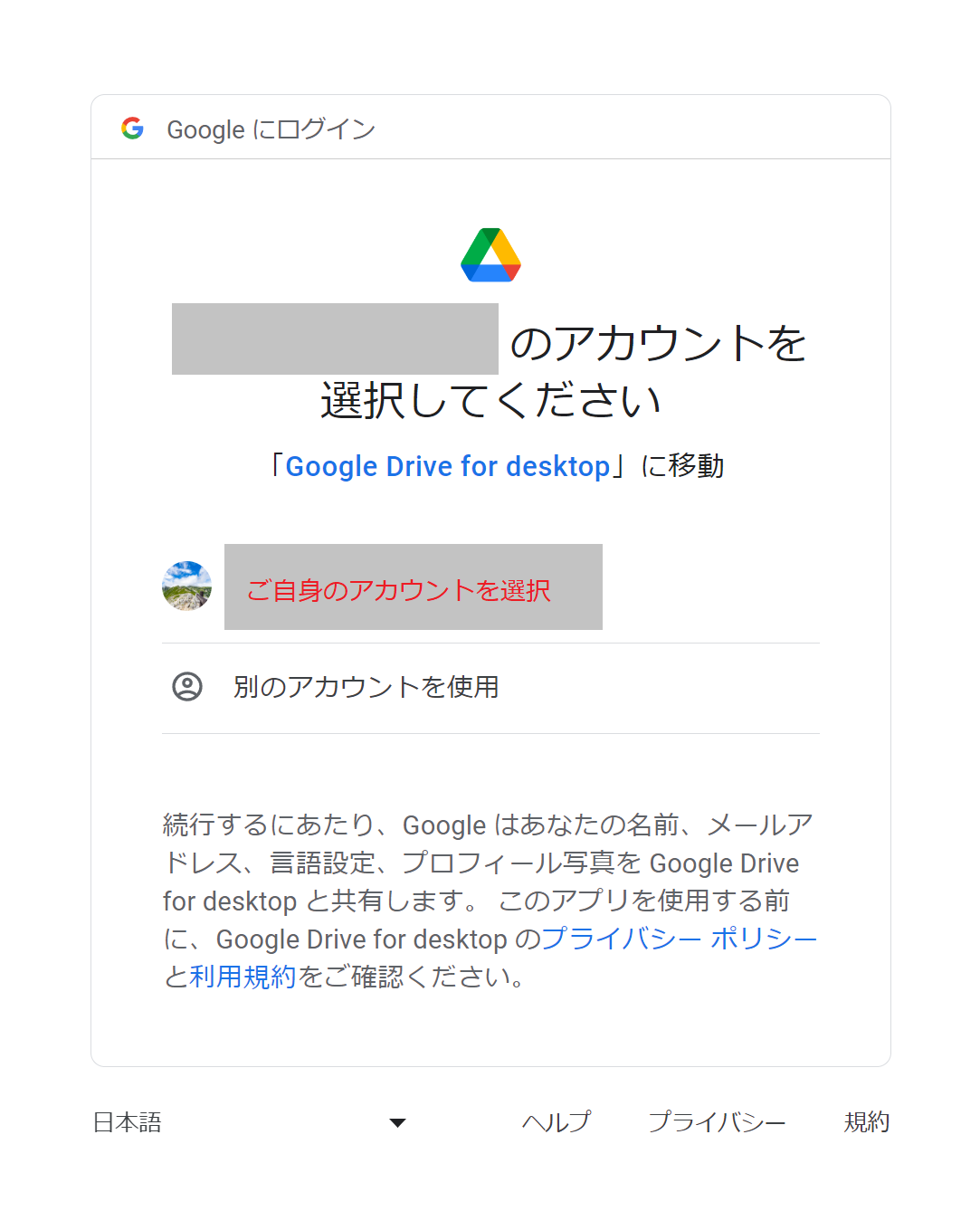
テキストデータを保存したGoogleドライブのアカウントを選択します。
アクセスのリクエストには「許可」をクリックします。
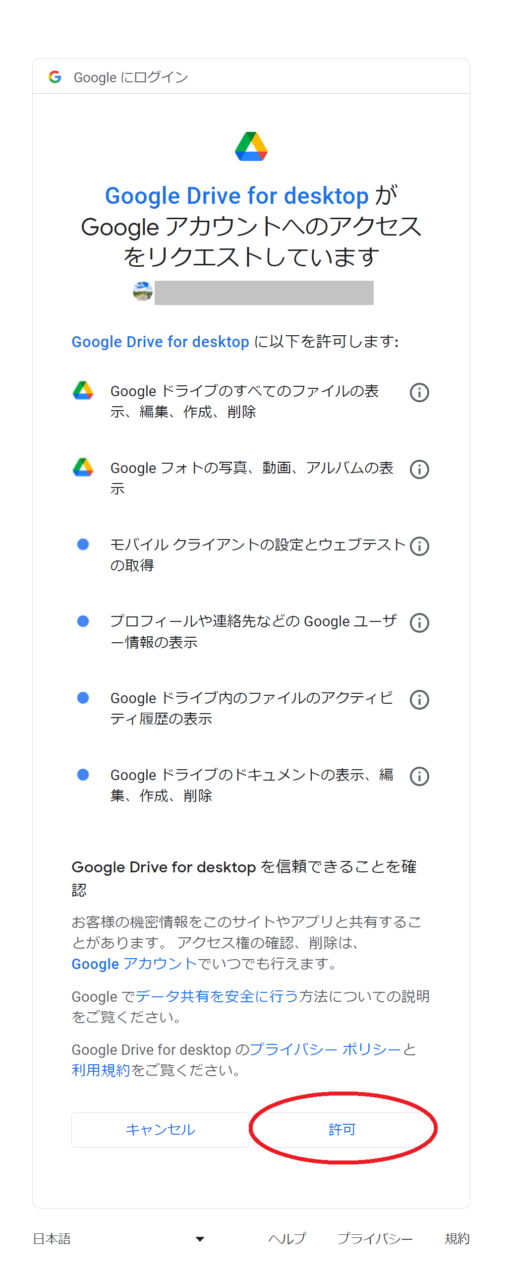
ウィンドウ下部に緑のチェックマークが付けばインストール完了です。

2.Googleドライブのパスを指定する
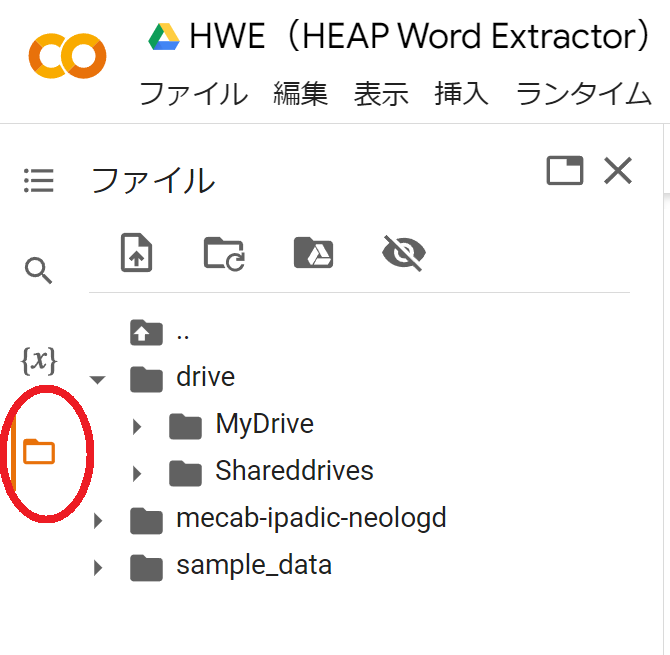
画面左横のフォルダーマークをクリックし、[Drive>Mydrive]フォルダから保存したテキストデータを探し、ファイル名横の[︙]から「パスをコピー」をクリックします。
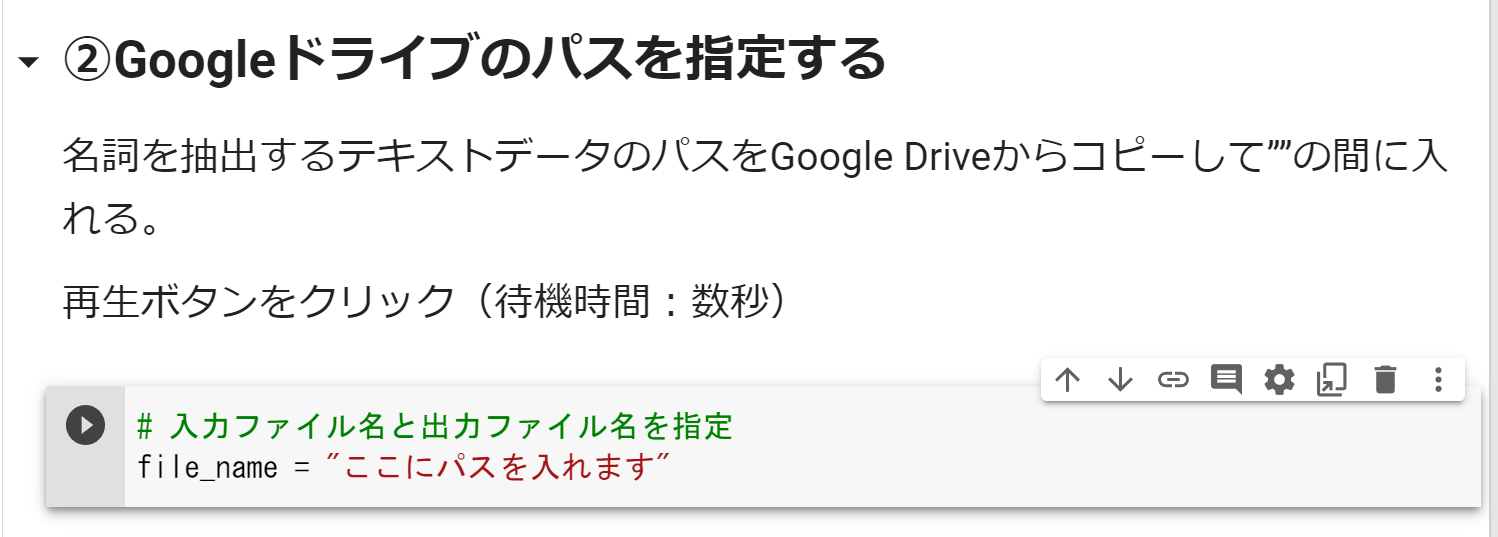
コピーしたパスを” ”の間に貼り付けて再生ボタンをクリックします。
3.単語を抽出する
再生ボタンをクリックすることで単語が抽出されたCSVファイルが元のテキストデータと同じフォルダに保存されます。ファイル名は「【テキストデータのファイル名】_辞書登録リスト(ANSI).csv」になります。
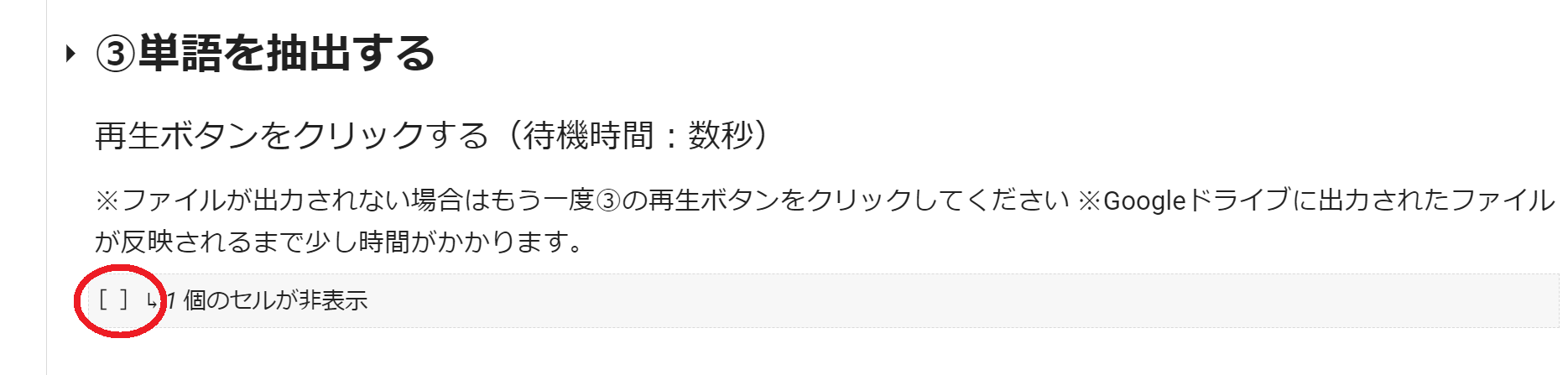
※数分経ってもCSVファイルが出力されない場合はもう一度③の再生ボタンをクリックしてください。
※Google Driveに出力されたファイルが反映されるまで少し時間がかかります。
4.CSVファイルの確認
出力したCSVファイルをダウンロードし、Excelで開きます。単語の読みが誤っていないか確認していきます。自動で単語の読みを作成しているため、専門用語や一部単語で読みが間違っている場合があります。必要に応じて修正していきます。
免責事項
- 本プログラムは無保証で提供されます。制作者は、プログラムの正確性、信頼性、適合性、および特定の目的への適用性についていかなる保証も行いません。
- プログラムの使用はユーザーの責任となります。制作者は、プログラムの使用によって生じるいかなる損害や損失についても責任を負いません。これには、直接的または間接的な損害、事業の中断、データの喪失、利益の損失などが含まれます。
- プログラムのセキュリティについて最善の努力を払っていますが、制作者は、プログラムの使用によるセキュリティ上の問題や損害について責任を負いません。ユーザーは自己の責任でプログラムのセキュリティを確保する必要があります。
- プログラムには他のオープンソースプロジェクトやライブラリが含まれる場合、それらのプロジェクトやライブラリの利用条件に従う必要があります。制作者は、他のプロジェクトやライブラリの動作、パフォーマンス、および互換性について保証しません。
- 制作者は、プログラムのバグや問題に関する修正、アップデート、およびサポートを保証しません。ユーザーは、自己の裁量でプログラムの改善や修正を行うことができます。
- 本免責事項は、プログラムの使用に関連するいかなる主張や訴訟においても適用されます。法的な制約や地域の法律によって、本免責事項の一部または全部が適用されない場合でも、残りの部分は有効とみなされます。
公開日:2023年6月28日
以下のGoogleフォームからあなたの感想や要望をお聞かせください。
https://forms.gle/4DkKF5ns13sxzRRk8